


Twin heritability models can tell you whatever you want to hear
The growing "missing heritability" problem within twin studies


Since the early findings from Genome-Wide Association Studies, the genetics community has been engaged in a debate over “missing heritability”1: the difference between estimates of heritability from these molecular studies and those from classical twin models. For some traits the difference is moderate: 45% of the heritability of height estimated with GWAS, compared to 70-80% estimated in twins. For some traits it is large large: 6% of the heritability of behavioral problems estimated from GWAS compared to 58% estimated from twins. But the difference is almost always there. What has garnered less attention is the missing heritability problem within twin studies, particularly for traits with complex gene-culture relationships. This debate, in fact, goes back decades and has been reignited by recent methodological developments.
I. The Classical Twin Design (CTD)
The classical twin design (CTD) for estimating heritability is deceptively simple, you’ve probably seen it presented in terms of monozygotic (MZ) and dizygotic (DZ) twin correlations like this:
Where A is the additive genetic component and C is the sibling shared environment2, which is presumed to be equal (more on this later). We know that DZ twins share half their genetic variation and MZ twins share all of it. It is then trivial to solve for A:
The beauty of this model is that it only needs two correlations to estimate a very interesting parameter. This means heritability can be estimated from observational twin registry data without requiring any genetic measurements at all. Since every trait can produce an estimate and each estimate can be the key result in a paper, twin registries have become an incredibly useful tool for publishing lots and lots of papers.
Unfortunately, that model is a fantasy. The reality looks something like this:
With the following additional parameters: dominant genetic effects (D), gene-gene interactions (A*A, but also all higher interaction components such as A*D), gene-(shared)-environment interactions (A*C), twin-specific shared environment (C-T), MZ/DZ specific shared environments (C-MZ, C-DZ, and excess genetic correlation in siblings due to assortative mating or “homogamy” (r-A). The full classic ACE estimate is then:
With all of the terms after A (as well as any higher order interactions) effectively assumed to be zero or to “cancel out”. That is a lot of assumptions baked into two simple equations! Notably, estimates of A can be severely inflated by violation of the Equal Environment Assumption (EEA) that C-MZ=C-DZ, gene-gene interactions, or gene-shared-environment interactions and the validity of these assumptions continues to be a major point of contention for analyses of twins (as we will soon see).
II. General models of genetic and cultural inheritance
Rather than make assumptions about the environment and familial assortment, a flurry of papers in the late 70’s and early 80’s proposed general models of genetic and cultural inheritance under a framework of path analysis:
Rice, Cloninger, Reich. (1978) AJHG: Proposing a basic model of cultural and genetic transmission with assortative mating for nuclear families (building off models by [Rao et al. (1976)].
Cloninger, Rice, Reich. (1979a) AJHG: Extending to models of combined cultural and genetic transmission in various two-parent families (including adoptees) and applied to IQ scores.
Cloninger, Rice, Reich. (1979b) AJHG: Further extending to models of combined cultural and genetic transmission in families with divorce, separation, or other complex living arrangements.
Rao, Morton, Cloninger (1979) Genome Res: Generalizing assortative mating to distinguish between direct phenotypic homogamy, social homogamy, or a mixture of both.
The basic idea is that the phenotype can be decomposed into the contribution of additive genetic variation (A, as above) which follows Mendelian segregation from parents; the strength of “cultural transmission” (i.e. child-rearing) between generations (β) and the effect of the transmitted cultural value on the offspring phenotype (B); the correlation of genetic or cultural values in mates due to assortment/homogamy (r-A, r-B respectively); the resulting correlation between genetic and cultural values within the offspring (W, sometimes referred to as “rGE”); and shared environments specific to each relationship class (C). Any other interactions or correlations are still assumed to be zero, leading to modified equations for twins that look like the following:
What makes this model “general” is that it can be defined for any relationship class (these are the “paths” in path analysis) and then fit jointly across all of them, thus identifying parameters that best explain the phenotypic relationships across many different observations. Notably, the EEA has been dropped, and each twin class can have a unique shared environment. But because these equations now have free parameters that do not cancel out (specifically C-MZ and C-DZ for twins), data on more distant relationships is needed to fit them. Moreover, if β = 1/2 (i.e. cultural transmission mimics additive genetic transmission) then the A and B parameters cannot be identified unless data on separated families are also available (adopted, fostered, etc; where genetics and environment can be distinguished by the family separation). This is an intuitive yet under-appreciated point: culture can look just like genetics and we need special assumptions and special data to disentangle the two.
Application to American IQ test data
To evaluate their new approach, [Cloninger, Rice, Reich. (1979a) AJHG] turned to data on IQ score correlations, which had been collected across a variety of different studies in the US and were thought to involve all of the processes described above. This data included measurements from a rich set of relationship classes including MZ/DZ twins, full siblings, unrelated siblings (i.e. adoptees), biological and foster parents, and spouses — showcasing the general applicability of this approach. Measurements from both intact and separated families meant the model could be identified even if cultural transmission matched genetic transmission. In this data, the CTD (i.e. MZ/DZ comparison only) estimated an additive heritability of 0.56, comparable to the moderately high heritabilities of IQ observed in other studies of the time and since. In contrast, the path analysis estimated an additive heritability of 0.33, with a nearly as large cultural transmission (B) component of 0.27. The deviation was in part explained by a highly significant estimate of unequal shared environments between MZ and DZ twins, whereas the DZ twin and full-sibling shared environments were inferred to be equivalent (i.e. no twin-specific shared environment). Another way to interpret this result is that MZ twins (who are identical in both genetics and cultural transmission) exhibit a phenotypic correlation so high that it does not generalize to more distant relatedness classes without an MZ-specific environmental component. We can see this in the figure below comparing the expected correlations from each model to the correlations that were actually observed: the CTD fits parent-offspring and foster parent-offspring relationships much worse — precisely the relationships where cultural transmission would be at play. Whatever is causing the similarity among MZ twins, whether genetic or cultural, is unique to MZ twins.
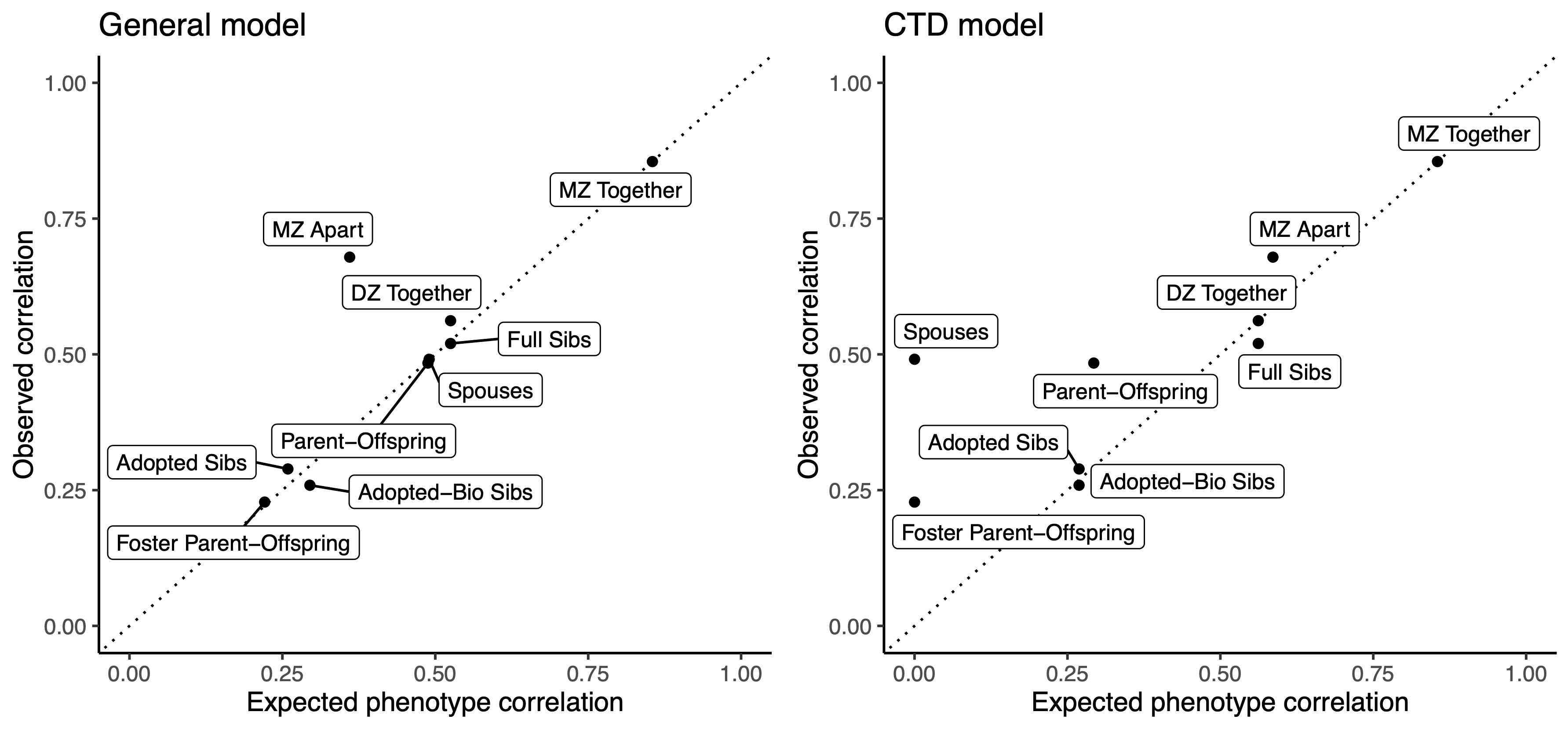
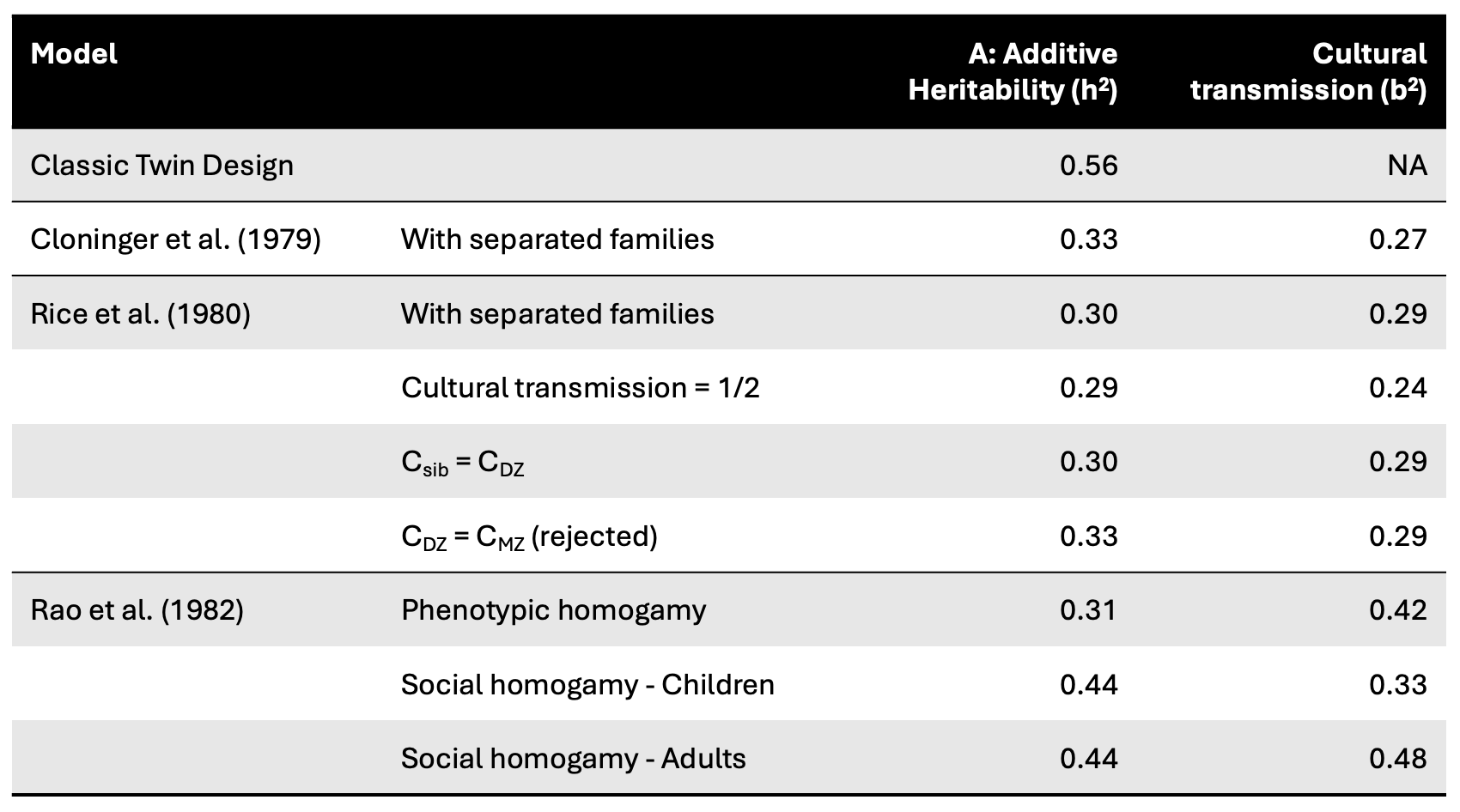
Further analyses of the same data by [Rice, Cloninger, Reich. (1980). Behav Genet] also found that a model where β = 1/2 could not be rejected, meaning that cultural transmission may in fact be mimicking genetic transmission. But the broader result held: the heritabilities from these general models consistently came in at around ~0.30 and roughly half the estimate from the CTD. An interesting historical footnote is that this estimate matches almost exactly an estimate of 0.55^2 = 0.30 made by Sewall Wright in 1931 in adults (with an estimate of ~0.50 in children), using an early derivation of the path analysis model (which was then essentially forgotten until the 70’s) shown below:

Finally, [Rao, Morton, Lalouel, Lew (1982) Genome Res] applied path models with generalizations of assortative mating, including assortment on non-genetic components of the phenotype (aka social homogamy, wherein people tend to marry neighbors or co-workers who are environmentally similar). Here the models deviated more substantially: “Under the phenotypic homogamy model, genetic heritability is h2 = 0.31 and cultural heritability is b2 = 0.42. The social homogamy model nearly reverses these heritabilities in children (h2 = 0.44, b2 = 0.33), with greater cultural heritability in adults (b2 = 0.48).”. Since the true mode of assortment was unknown, these differences could not be resolved. However, there was general agreement that cultural transmission was as or more important as genetic transmission and MZ/DZ environmental equivalence provided poor fit to the data. The full set of estimates from all three studies are summarized in the table below:
Was it too much, too soon?
It is remarkable to see the level of rigor and clarity in these papers, published over a short period of time by a small group of researchers. One gets the sense that there were almost too many key findings presented and at such a rapid pace that the field was unable to fully process all of their implications. Across these papers the authors:
Propose a general theoretical model that captures the major components of phenotypic variance: genetic transmission, cultural transmission, gene-culture correlations, assortative mating on both values, as well as both direct and social assortative mating.
Derive path models not just for conventional nuclear families, but for multiple generations, adopted/foster relationships, and complex “broken” families where offspring are raised by distant relatives or even a series of relatives.
Stress that genetic and cultural transmission can appear indistinguishable and then show that this is likely the case (or at least cannot be rejected) for IQ.
Causally demonstrate substantial and highly significant violations of the equal environment assumption — the linchpin of conventional twin analyses.
Implicitly eschew estimation of dominance and epistasis in favor of better modeling of shared environment3, a decision that would be vindicated decades later with the finding that dominance effects on complex traits are minimal.
Investigate “index” estimates of the home environment and demonstrate that these are often crude proxies for IQ scores themselves, potentially inflating estimates of heritability rather than identifying moderators.
Call for the careful collection of environmental indices that could be integrated into path analysis to identify the sources and modifiers of cultural transmission.
Repeatedly stress that model fitting is merely a way of explaining the data and that the fundamental goal of genetic epidemiology should not be merely fitting numbers to paths but using a variety of models to identify the underlying environmental and cultural causes4.
The breadth of modeling also cannot be overstated. Within a year of introducing their joint genetic-cultural models, Cloninger (1979b) were describing models of complex, fractured family structures for divorce and adoption while accounting for non-random placement and assortment:

In short, I think these papers simply went too hard5. They proposed an answer to the question of gene-culture transmission that is so comprehensive and definitive in its implications that it was easier to ignore it. Each study concluded with an explicit call to abandon simple parent/offspring correlations and collect richer and more detailed multigenerational data and apply theory-driven models. For example, from Rice et al. (1980):
“Finally, it is disappointing to note the paucity of data with multiple classes of relatives in the literature. This no doubt reflects the fact that observations made on remote relatives provide little additional information under the polygenic model. What could be simpler than to estimate VA from a parent-offspring correlation and VD from the sibling correlation. Unfortunately, failure to allow for cultural inheritance precludes its discovery and can lead to serious methodological difficulties. We hope the results described above have clarified the need for multigenerational data as well as comprehensive theoretical models for the analysis of behavioral traits. Such an approach to the interpretation and validation of phenotypic and environmental variables in families is rigorous without being nihilistic and provides a fruitful strategy for analyzing the development (or pathogenesis) of complex behavioral traits”
However, this “rigorous without being nihilistic” approach did not, in fact, become the paradigm. The field persisted for decades with larger and larger twin studies and simple CTD analyses. Periodically, someone like Robert Plomin would re-demonstrate that the CTD heritability of IQ was ~60% (953 citations) and someone like Marcus Feldman would re-iterate that general path models provide much lower estimates and evidence of a substantial cultural component (51 citations). Gradually, an empire built up around a small core of twin registries, dutifully computing 2*(rMZ-rDZ) and churning out estimates of A=50% and C=0-20% for anything that could be measured. The empire even developed laws, the second of which was: “the effect of being raised in the same family is smaller than the effect of genes”6. And so it went for several decades.
III. The empire strikes back: extended twin studies
The issues of assortative mating and gene-culture transmission did not go away, however, and since the early 2000’s, new twin-based models have emerged to address them. Rather than relaxing the EEA and collecting many different intact and separated relationship classes, these models put twins at the center but collect measurements from additional relatives around them. The basic idea is that phenotypic correlations with parents/spouses of twins can inform the amount and type of assortative mating, and phenotypic correlations with siblings/offspring the amount and type of cultural transmission. Recently, these methods have been extended and applied to the phenotype of educational attainment — which is easy to collect and likely to be under both assortative mating and cultural influence — and thus provide for interesting empirical comparisons. Let us go through some representative studies:

Assortative mating and the Nuclear Twin and Family Design (NTFD)
The NTFD attempts to model non-zero A-M (assortative mating) and C-T (twin-specific environments) by incorporating phenotypic correlations from parents and siblings of twins. If parental phenotypes are correlated, that is indicative of assortative mating which could be deflating heritability. If DZ twins are more correlated than full siblings, that is indicative of a “twin specific environment”. In both cases, the (now re-defined) sibling shared environment (C) gets cut down. For twin correlations, the equations look very similar to those above from Cloninger (1979) except the EEA is enforced (C-MZ must equal C-DZ).
[Wolfram, Morris (2023)] applied the NTFD to educational attainment data from 982 German families. The conventional CTD estimated an additive heritability of 34% and a shared environment effect (C) of 43%. The NTFD produced two baseline models that had equivalent likelihoods but very different estimates of heritability: 51% for the phenotypic homogamy model and 36% for the social homogamy model7. In both cases, the NTFD models re-assigned a substantial proportion of the shared environmental effect (C) to twin-specific environments and genetics (in the phenotypic homogamy model) or phenotypic and passive transmission (in the social homogamy model). So we are left with two substantially different interpretations of the contribution of genetics (34%-36% vs 51%) and two substantially different interpretations of the contribution of shared environment (10%-11% vs 43%). However, in both cases, assortative mating was estimated to bias the CTD heritability down, either by a lot (phenotypic homogamy) or by a little (social homogamy).

Indirect assortative mating (iAM) and the Children of Twins and Siblings (COTS)
To help disentangle phenotypic from social homogamy, [Sunde et al. (2024b)] recently proposed two “indirect assortative mating” (iAM) twin models that incorporate information on the spouses of twins and their offspring. They cleverly re-define assortative mating as a process that occurs on a latent “sorting factor”, which can then be driven by genetic/cultural/environmental components to varying degrees and is correlated with the focal phenotype. This enables a model where assortative mating is a continuous mix of different processes, rather than being either all direct/phenotypic or all social as in prior work. As we saw before, if spouses are more genetically correlated than chance, the CTD estimate of heritability will be biased down. But if spouses are more environmentally correlated, this may likewise deflate the estimates of environmental effects.
To estimate these components, the authors first propose the “iAM-ACE” model, which uses information from MZs/DZs/full-siblings and their spouses. Whereas the CTD leveraged two observations (rMZ vs. rDZ, or three if including non-twin full-siblings), spouses provide a total of eight observations (or twelve if including full-siblings) and it is worth briefly walking through how these contribute to model identifiability:
The twin correlations are related to the genetic (A) and shared environment components of the focal trait like in the CTD.
The twin correlations with their spouses are related to the partner similarity on the latent sorting factor and the covariance between the sorting factor and the focal trait.
The correlation of twins with their in-laws and the correlation of in-laws with in-laws are related to the genetic and shared environment components of the sorting factor in different ways. For example, if homogamy was entirely social (i.e. non-genetic), then the twin/in-law correlations would be the same for MZ and DZ families.
Finally, the differences between DZ twins and full-siblings along all of the above relationships enable the estimation of twin-specific environmental effects.
This model was applied to twin and sibling data on educational attainment from Norwegian registries. With the conventional ACE/CTD model, the heritability of educational attainment was estimated at 50% with a shared environment of 19% (note: these estimates are substantially different from the German data in Wolfram, Morris (2023)). For the sorting factor, the iAM-ACE model estimated a heritability of 38%, a twin/sibling shared environment of 61%, and just 2% for non-shared/idiosyncratic environment. Thus, the process of assortative mating on educational attainment was less heritable than educational attainment itself and largely driven by social homogamy along the sibling shared environment.
For educational attainment itself, the iAM-ACE model in turn estimated a heritability of 44% — lower than that of the CTD without modeling assortative mating. Moreover, a model of direct/phenotypic assortment could be formally tested by constraining the ACE effects on the sorting factor to be identical to those on educational attainment itself (i.e. the sorting factor is just a surrogate of the focal phenotype), and this model was rejected. Thus, indirect assortment was estimated to be more environmental than genetic and this actually biased the CTD estimates upwards.

Next, the authors extend their model to additionally estimate cultural transmission through the inclusion of children of twins (“iAM-COTS”). In contrast to the Cloninger path models, here cultural transmission is partitioned into (a) direct effects of the parental phenotype and (b) passive effects of the sibling shared environment in parents. The key to identifiability is that, in MZ twins, the genetic parental-offspring (PO) relationship is the same as the genetic avuncular-offspring (AO) relationship. Thus, if the PO correlation is higher than the AO correlation, that is evidence of a direct parental phenotypic/cultural effect on the offspring, whereas if they are equal that is evidence of a “dynastic” genetic or environmental effect on the offspring (similar reasoning was recently applied to non-twin data using polygenic scores [Nivard et al. (2024)]). Indeed, in MZ families in this data, the PO correlation (0.33) was indistinguishable from the AO correlation (0.34), supporting the presence of dynastic effects. Finally, the model additionally quantifies the contribution of gene-environment correlation (rGE, or W in the Cloninger models) that builds up through assortative mating (assuming these correlations are the same across generations). Applied to the same Norwegian data, the iAM-COTS model estimated a sorting factor that was even less heritable (30%, down from 38%) but with a sizable rGE component (17%). The impact of genetic effects and rGEs is complicated, so that even though the heritability decreased, the expected spousal genetic correlation actually increased (from 0.26 to 0.33). Finally, the heritability of educational attainment was estimated to be 41% in the parents/twins and 39% in their offspring (down from 44% by the iAM-ACE model and 50% by the CTD).
In short, assortative mating actually biased the CTD estimate of heritability upward, due to an inferred “sorting factor” driven by substantial social homogamy (spousal sorting driven by non-genetic shared environment) and a moderate genetic component. It also inflated the CTD estimate of the shared environment, due to a mix of rGE and twin-specific shared environments. The former result is diametrically opposite to that of Wolfram, Morris (2023), which found that the CTD estimate of heritability was biased down under either form of homogamy.
Relaxing the equal environment assumption and the Twin Family Design (TFD)
While both of the above extended twin models retained the equal environment assumption, the use of spouses and children also allows for the EEA assumption to be relaxed. Such a model was recently proposed by [Bingley et al. (2023)] and also applied to educational attainment.
First, for disentangling the parameters of assortative mating, the authors employ the same intuition as the iAM-ACE model: spousal correlations are a consequence of genetic and environmental homogamy, and these two parameters can be estimated by incorporating the phenotypic correlations of twins/in-laws and in-laws/in-laws. When accounting for assortative mating in this way, the model estimates a heritability of 41% and a shared environment of 18% for educational attainment, using data from the Danish Twins Registry. We can treat this as the CTD estimate since it only uses extended relatives to adjust for assortative mating.
Next, to relax the EEA, children of twin/spouses are added just like in the iAM-COTS model. However, in an echo of Cloninger8, rather than fixing the shared environment between twins to be identical (C-MZ = C-DZ), the model fixes the avuncular shared environment to be identical: the environmental sharing between twins and their nieces/nephews is assumed to be the same as between the spouses of twins and their nieces/nephews. The EEA is the central dogma of twin studies, so it is worth thinking through the implications of this change. A primary concern regarding the EEA is that MZ twins may be treated by parents, society, and each other more similarly than DZ twins, inflating their shared environment and trait similarity. With the equal avuncular environments assumption, MZ twins are now allowed to have a unique shared environment. A new concern may be that twins, who are related to their nieces/nephews by blood (and, for MZs, as related as their biological parent), will have more environmental similarity with them than their spouse. The authors argue this assumption is weaker than the EEA.
Reapplying this relaxed EEA model to the same data, they find that the estimate of heritability decreases substantially to 10% (from the AM-CTD estimate of 41%), with a large (49%) compensatory contribution from the shared environment. The authors also did something clever which none of the other studies have attempted: they validated their model! Specifically, they randomly split their twin sample in half, estimated parameters in one half, and evaluated the parameter fit in the other independent half. Every single estimate was within the 95% confidence interval of the model fit, suggesting that this model is able to generalize to unseen samples from the same population (see their Appendix Table A2). Consistency does not imply truth, but it is nice to see.

Finally, the authors apply this model to other available measurements: earnings, income, and assets. In all instances, the AM-CTD estimates are substantial (42-60%) but are dramatically reduced in the relaxed EEA model (13-17%). In some sense we have come full circle, with this model starting from the CTD but working towards the general path analysis of Cloninger et al. by relaxing environmental assumptions, observing substantially lower estimates in the process yet again.
IV. Interpretation across models

So we have a range of twin-based estimates which from as low as 10% (Bingley) to as high as 51% (Wolfram). Which estimate is right? Typically one would triangulate across methods with different modeling assumptions. But the assumptions in these methods are not just different, they are often opposite. It is not possible to triangulate between a method that assumes equal environments and one that assumes unequal environments when their estimates disagree. These methods also all share an assumption: that genotype and environment do not interact (AxC is zero, in addition to all the other interactions). This is a problem because the methods are often applied to different relationship classes and family types. So if there are interactions with the shared environment that differ by relationship class, the methods could all be wrong in different ways. We can, however, draw a few general conclusions:
The CTD generally estimates a large A, small C, and large E component.
Twin correlations do not generalize within nuclear families: DZ twins exhibit higher correlations than full-siblings. This is accommodated with a “twin-specific” shared environment in extended twin models.
Twin correlations do not generalize between twin families. Bingley/Cloninger estimate a significant difference in the shared environment effects between MZ and DZ twins.
Twin correlations do not generalize to broader population correlations. Cloninger/Rice (and, more recently, [Collado et al. (2023)]) estimated heritability parameters that were significantly lower than that of any twin model.
Assortative mating can bias CTD estimates either up or down. Wolfram, Morris found downward bias, which was strongest under direct/phenotypic homogamy. In contrast, Sunde et al. estimated that homogamy was largely social and moderately heritable, leading to upward bias in the CTD heritability estimate.
Models with low heritability can provide a very good fit to extended trait correlations by either allowing for unique environments (Bingley, Cloninger) or very strong latent assortative mating in non-twins (Collado).
This does not necessarily mean CTD estimates are wrong. But they are, at best, estimating twin-specific parameters that do not generalize to the population without additional modeling adjustments. If you happen to be born with a twin, those correlations can be of use to you. For the rest of us, we still do not know which assumptions are reasonable.
What about molecular models?
There is, of course, an alternative way of estimating heritability, which relies on the collection of large-scale genetic data within and between families. This approach, particularly the within-family estimates, makes very few environmental assumptions but it requires the causal genetic variation to actually be captured by the genetic data (either directly or through correlation). What have we learned from molecular methods?
There are now multiple lines of evidence for cultural/environmental transmission for educational attainment and other behavioral traits: (1) polygenic scores computed in parents are associated with the phenotypes in their children to a larger extant than expected from simple assortative mating [Kong et al. (2018)]; (2) the within-family heritability (which is what twin models seek to estimate in A) is substantially lower than population-level heritability (which includes cultural transmission and gene-environment correlation); (3) adjustment for passive environmental factors such as birth place significantly reduces the heritability [Abdellaoui et al. (2022)]. For educational attainment, the best estimate of total within-family heritability is 9-17% but with very wide error bars [Young et al. (2018)] and the estimate from common variants (which typically explain the majority of heritability) is 4% with very narrow error bars [Howe et al. (2022)]. These too are consistent with the low Bingley/Collado results of ~10%.
Molecular models can also provide some insights regarding homogamy. [Okbay et al. (2022)] observed much higher than expected polygenic score correlations between spouses, suggestive of latent assortment. However, these polygenic scores are known to be inflated by some amount of population stratification, which could look just like genetic correlation between spouses if social homogamy tracks with geography. CTD heritability estimates were also recently shown to be incompatible with the level of spousal polygenic score correlation for educational attainment as well as for height [Young (2023)]. So either CTD estimates are inflated, or the polygenic score correlation is biased. Thus the large twin-based estimates are outliers in multiple respects.
V. The takeaway
The Classical Twin Design seems so simple — just compute two correlations and take the difference — but this merely is a consequence of assuming away all of the complexities. Extended twin models that incorporate relatives can interrogate some of these assumptions, but they do not yet agree on estimates, nor even on which assumptions are being violated. Forty years ago, Cloninger and colleagues demonstrated that lifting the equal environment assumption between twins (by using data from separated families) produced substantially lower estimates of heritability and a large cultural transmission component. This has now been replicated and expanded on by shifting the EEA to avuncular relationships, demonstrating even lower estimates for educational attainment. Results from molecular modeling also appear to be incompatible with the CTD estimates, but may have their own biases. So the next time someone brings up twin heritability, just ask them: which estimate would they like?
Further reading
Marcus Feldman and Sohini Ramachandran on the history of path analysis and the debates over the heritability of IQ.
Lindon Eaves on the history of the CTD, path analysis, and the development of extended twin family models.
If you read just one gene-culture path analysis paper, make it the methods comparison of Rice (1980) which succinctly summarizes the core approaches. If you read two path analysis papers, make the second one the thesis of Otto (1994), which derives all of the key components of gene-culture transmission models and applies them to IQ and personality.
In prior work on assortative mating, Sunde et al. (2024a) had an excellent supplementary note on assortative mating and they again do not disappoint, the supplementary note in Sunde et al. (2024b) provides a very good narrative discussion of extended twin models and their intuition
I’m using the popular term here though I personally think the term “missing” is more confusing than anything. What we actually want to know is: (1) whether different models are estimating the same population parameter; (2) for models that do intend to estimate the same parameter, why their estimates disagree; (3) for models that do not intend estimate the same parameter, whether their estimates are compatible. In the case of twin studies, they typically seek to estimate the same parameter —“A”, the causal, additive genetic component of the trait — so we can focus on (2).
The sibling shared environment (C) is really only defined tautologically: it is the environmental influence within families that makes siblings more similar in their traits. For example, a divorce would generally be considered part of the family environment, but if divorce makes siblings more different (e.g. by straining their relationships, or leading one to be the “favorite”, etc.) then it will statistically not be considered part of the shared environment defined by C. For more discussion see [Turkheimer & Waldron (2000)].
“Two schools have developed genetic analysis of quantitative data. One radically simplifies environmental effects to provide an estimate of dominance deviations; the other realistically elaborates environmental effects, thereby risking indeterminancy even when the estimate of dominance deviations is sacrificed. We have argued that the second approach is preferable, since environment common to relatives is likely to be a more important source of variation than is dominance.” ~ Rao et al. (1976)
“Indices of home environment offer the promise of increasing the precision of estimates of cultural inheritance and reducing the number of classes of relatives needed to specify the values of the parameters. However, as discussed in relation to our anlaysis of Burks' culture index, the use of such indices has serious pitfalls unless sufficient information is available to test the fit of that model without assuming the index is an unbiased estimate of non-genetic factors. Nevertheless, evaluating indices is probably the most fruitful aspect of the analysis of multifactorial traits in terms of defining hypotheses which are potentially testable and socially or therapeutically beneficial, and so merits further study as noted elsewhere” ~ Cloninger et al. (1979a)
More generally, this was a remarkably productive time for Cloninger: in 1981 he used a “cross-fostering” design to definitively demonstrate that alcohol abuse was heritable (>2800 citations); in 1986 he proposed a novel personality model of anxiety (>1900 citations); then in 1987 he linked this model to alcoholism (>3500 citations) and expanded his theory of personality which continues to be widely used (>5700 citations). In this work, Cloninger consistently emphasized the importance of theory rather than data-driven factor analysis for the construction of psychological measurements.
Several thousand important words were then deployed to explain that this law does not imply that genes are more powerful than environments, or even the environments within families (as long as they influence the offspring differently). But few seemed to have read that far.
Working from these baseline models, the authors further drop paths that do not worsen the model fit (in fact, the fit remains exactly the same), at which point the direct/phenotypic homogamy model has the highest approximate likelihood. The extent to which this type of in-sample model pruning produces valid model comparisons is unclear to me and the authors do not justify their approach with simulations or bootstrapping. For more discussion of identification with model constraints see Sections 7-8 of [Goldberger 2002] (thank you to Richárd K for the reference).
But unlike the Cloninger et al. analyses, the EEA cannot be fully lifted because this model does not include separated families.
This is quite an interesting deep dive into the genetic complexities of estimating heritability. I just wrote about this topic from the perspective of James R. Flynn's work on individual and social multipliers, that is aspects of our environment that twin studies can't measure. What do you think on that topic? https://open.substack.com/pub/eclecticinquiries/p/on-race-racism-iq-and-heritability?r=4952v2&utm_campaign=post&utm_medium=web
Very good, hard to fully understand from scratch, but I will definitely come back for more. I‘d love to see a simplified version of the article!